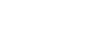上一期谈到如果想创建一个能支持全栈运维的 MOSS 或者贾维斯这样的机器人助理,它的大脑必须具备 IT 运维的专业知识,重新训练或者微调出一个运维大模型当然是最直接的办法,但它在知识访问控制便利性、知识更新的灵活性以及总体成本和复杂度上都让一般企业望而却步。随着预训练大模型的不断发展,通识能力越来越强,能不能在通识模型的基础上外挂专业知识库来增强大模型生成答案的专业性呢?这就是所谓 “检索增强生成”(Retrieval-Augmented Generation,RAG)。
它的本质是一种提示词工程(Prompt Engineering),也就是说我们先到一个知识库内把专业性的知识找到,把它们作为问题提示词的一部分交给大语言模型做参考,即便大模型没有相关领域的知识细节,它也可以根据自己已具备的通识,参考问题里的知识提示,然后给出更具专业性的解答。这种技术的核心在于知识的 “检索”,也就是名称里 Retrieval 的由来。直接用问题里的关键词去匹配知识库里的文本显然既难于操作、命中率也会极低,普遍采用的方式是把知识库里的文本拆成片段,每个片段编码成多维向量,我们知道在互联网行业普遍采用的客户画像,就是通过这种多维属性构成的向量来刻画的,比如一群客户在多重属性构成的向量空间里相距很近,那么这些客户的各类属性肯定就是 “相似” 的,于是我们就可以刻画出这个群体客户肖像帮助我们定向投放商品。既然我们可以用这种技术来筛选客户,那么只需要把知识片段也打上各种属性标签,我们也可以来定位与问题相关的所有知识片段,只是这里的知识片段的 “属性” 是需要通过对这段知识的语义理解来量化的,不过这不用担心,很多大语言模型的第一步就是要对词语进行这样的属性标记,这个标记过程称为嵌入(Embedding)。如今很多大语言模型都把这个能力开放出来,于是我们可以把问题和知识片段都进行这样的 Embedding,通过计算就可以快速定位相关的知识。比如下图就是我使用 OpenAI 开放的 Ada-002 模型的 Embedding API 生成的关于我个人简历的 1536 维向量。

下面的图中 /ai 是向没有知识检索的 AI 提问,/ask 是向有知识检索的 AI 的提问,可以明显看出二者在问题回答质量上的差别:
现在市面流行的很多上载 PDF 后就可对文章内容进行提问的 AI 应用都是采用类似方式实现,在 OpenAI 首次开发者大会上推出的 GPTs 和 Assistants API 等则直接把分片、嵌入、检索等操作傻瓜化来帮你更方便的创建类似应用,可见检索增强生成的巨大潜力。但作为一款要求准确性极高严肃运维应用,直接使用这些消费级检索生成显然是不够的,我们需要提供专为 IT 运维优化的检索增强生成技术。
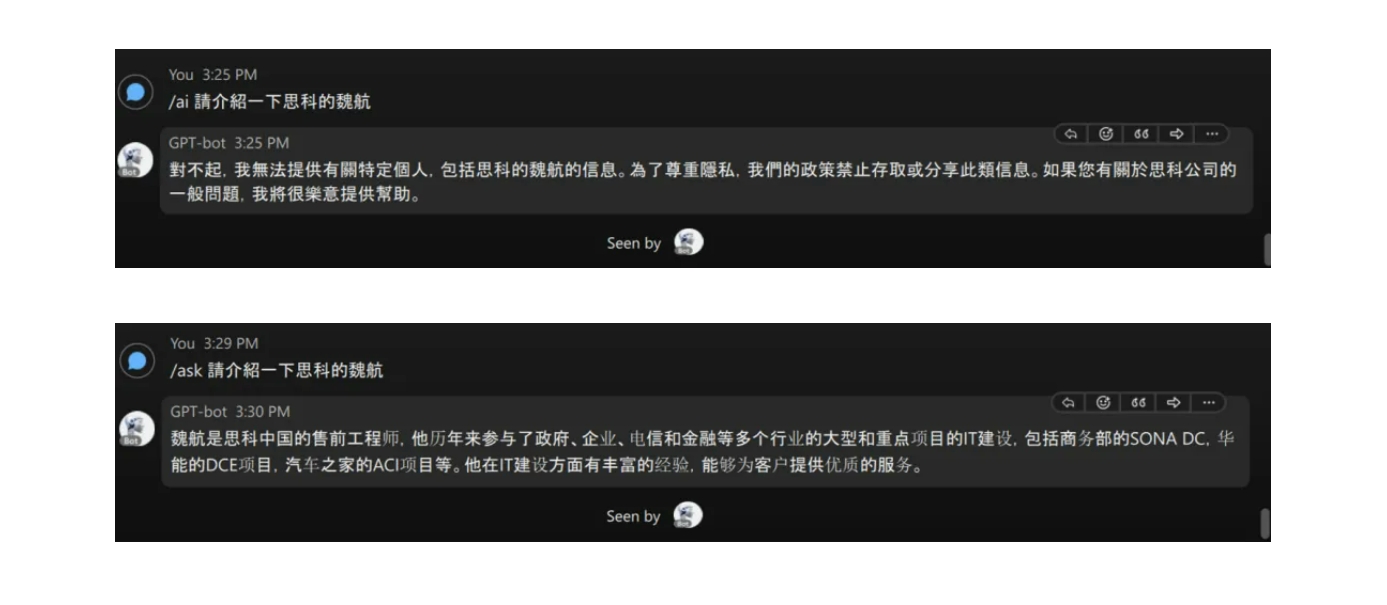
首先我们需要在上下文窗口值和知识理解完整性之间取得平衡。任何大语言模型都有一个输入输出的上下文窗口限制,很显然这个窗口越大越好,否则知识片段太小,即便分多次提交多个知识片段,也很难重建其中各种微妙的关联信息,这种不完整或碎片化的知识理解会极大的恶化最终的推理质量。这里要注意的是很多大模型为了市场宣传,给出的窗口值远大于其能产生正确搜索的窗口值,而且不同类型的长文档能产生更高搜索正确率的部位也不同,比如 AI 市场分析专家 Greg Kamradt 就在 X 上分享了他对两款大语言模型搜索长文档能力的对比图:【1】
可以看到左侧号称最大 200K Token(中文相当于十几万字)窗口,但在这个测试里准确率较高的最大窗口值只有 24K(较多绿色的区域),右边虽然标称只有 128K,但最佳检索窗口则高达 91K。不仅不同模型,不同类型文档也有差异,所以我们提供的知识库会根据不同模型,针对思科知识文档类型进行自适应的动态优化,以提高知识搜索的准确率。
上下文窗口不仅要容纳问题,还需要考虑回答以及多轮会话的上下文,所以大型文档必然需要切分,而一般按固定 Token 数和固定重叠率的切分方式很可能会把关联性极强的知识点切到了不同片段,从而在向量化时被其他知识点所掩盖。而且文档中还有大量非文字描述内容,比如复杂表格、图片等等,都需要特别处理。因此我们开发了专门的工具,在相关知识领域专家的辅助下通过标记进行切分,对特殊信息做额外转换,针对思科常见的知识文档和高级服务案例使用最佳实践方式实现向量化知识库转换。
我们还根据经验和最佳实践选取适合思科知识内容的 Embedding 和检索算法,选择包括 Map Reduce、Map Refine、Map Rerank、上下文压缩、前瞻性主动检索增强生成(FLARE)在内的多种技巧使 RAG 能够适应各种运维案例下的检索场景,最大化 AI 生成响应的相关性、准确性和效率。
喂给大模型的除了知识,还有 IT 全栈系统的实时状态,它们应当根据问题提示从特定的外部系统获得(比如 API 调用),然后与相关检索到的知识一起让大语言模型推理生成答案。
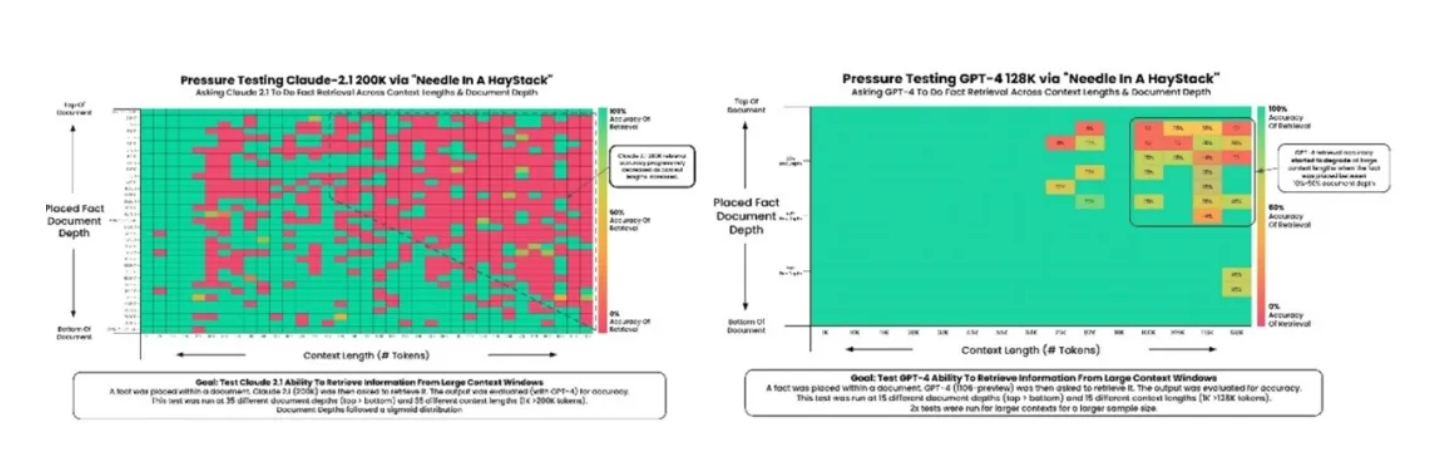
最后也是最关键的,就是如何弥补一般通识模型因为对专业知识的缺乏而导致推理误差这一固有缺陷,这就好比给只会中文的你一本拉丁语字典,完全不懂拉丁语语法的你也无法和别人用拉丁语自由交流一样。外挂的知识通过良好的提示工程可以重建知识逻辑,但提示词所涉及的全栈系统状态信息的关联关系则是一个复杂的巨型知识图谱,有统计一个数据中心平均有百万级的测量指标(图谱中的图节点),相互可以构成千万级别的关联关系(图节点之间的边),这几乎不可能用提示工程重建如此复杂的关系。解决方案就是把全栈运维细分为不同场景,大力借助每个场景内高度发达的全栈观察力(FSO)工具,这些工具自身就具备把大量复杂的测量指标、日志、事件、跟踪等原始数据通过自带的 AI 分析,得出上下文丰富的洞察信息的能力。思科既是 APM 厂商、也是交换机、路由器和转发芯片厂商,同时还是全球路由骨干、云、企业网和终端系统端到端监测工具的厂商,从高度、深度和广度上拥有最齐全的 FSO 工具【2】。
思科非常擅长如何按运维场景的最佳实践把自己各领域 FSO 工具的洞察进行关联,把原始运维数据的千万级别的边/节点的知识关系简化为AI处理之后洞察信息之间简单的逻辑关系,从而大大简化了运维知识图谱,再借助我们精心设计的 Few-shot、思维链(Chain of Thinking)和由简入繁(Least to Most)等提示工程技巧,使复杂运维的高精度推理成为可能。

虽然谈了这么多增强检索的能力,但思科仍然同时在对基础模型进行优化,就好比同样拿着运维手册,大学生和中学生还是不同的,所以思科的全栈运维的大脑,是IT运维优化的大模型与IT运维优化的检索增强生成这二者的结合。
现在我们有了智慧的大脑、发达的 FSO 工具,最终如何构建一个完整的全栈运维 AI 智能体(AI Agent)呢?OpenAI 首次开发者大会对整个行业智能体的影响会是什么?除了思科的 FSO,其他的厂商的工具能否也被我们的 AI 智能体所利用?最终这个智能体能解决什么样的实际运维问题呢?我们将在本系列的下一期详细解答,敬请期待。